Towards Scalable Pre-training of Visual Tokenizers for Generation












Abstract
A unified visual tokenizer pre-training framework (VTP) improves generative performance by optimizing image-text contrastive, self-supervised, and reconstruction losses, leading to better scaling properties and higher zero-shot accuracy and faster convergence.
The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the ``pre-training scaling problem`` and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
Community
GitHub codes: https://github.com/MiniMax-AI/VTP
Huggingface weights: https://huggingface.co/collections/MiniMaxAI/vtp
collaborated with HUST Vision Lab: https://github.com/hustvl

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation (2025)
- Temporal-Visual Semantic Alignment: A Unified Architecture for Transferring Spatial Priors from Vision Models to Zero-Shot Temporal Tasks (2025)
- DINO-Tok: Adapting DINO for Visual Tokenizers (2025)
- InternVideo-Next: Towards General Video Foundation Models without Video-Text Supervision (2025)
- Visual Generation Tuning (2025)
- Repulsor: Accelerating Generative Modeling with a Contrastive Memory Bank (2025)
- RecTok: Reconstruction Distillation along Rectified Flow (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend

This gets at a core bottleneck in generative vision: tokenizers optimized for pixels don’t scale cognition. VTP’s shift toward semantic-first latent spaces mirrors what we’ve already learned in language — understanding must precede generation. The fact that generation quality now scales with tokenizer pretraining FLOPs is the real breakthrough here. This feels like a necessary correction to the “just reconstruct better” era of VAEs and a strong signal that vision models are finally being trained to think, not just compress.

arXiv lens breakdown of this paper 👉 https://arxivlens.com/PaperView/Details/towards-scalable-pre-training-of-visual-tokenizers-for-generation-8866-f2bc9df0
- Key Findings
- Executive Summary
- Detailed Breakdown
- Practical Applications

Here are the main results of VTP (Visual Tokenizer Pre-training), which solves the "pre-training scaling problem" by redesigning visual tokenizer training to jointly optimize representation learning (CLIP + self-supervised learning) with reconstruction.
1. The Core Finding: Understanding is the Key Driver of Generation
The paper establishes a strong positive correlation between a tokenizer's semantic understanding capability and its generative performance. Unlike conventional wisdom that prioritizes pixel-perfect reconstruction, VTP demonstrates that high-level semantic comprehension in the latent space is what enables better generation.
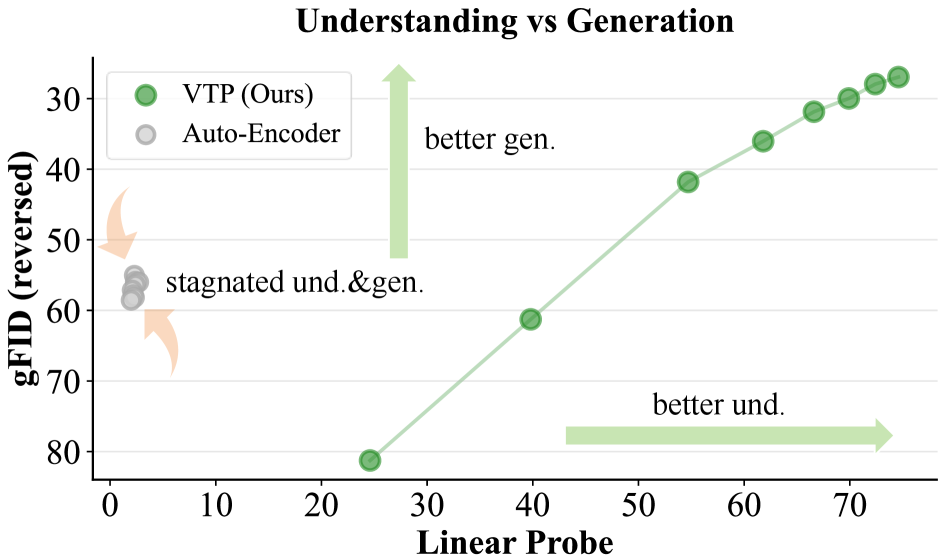
Figure 2: Understanding is a key driver of generation. The semantic quality of the latent space correlates strongly with generative performance.
2. The Scaling Paradox (Reconstruction-Only Fails)
When scaling up standard autoencoders trained only on reconstruction, the paper reveals a paradox: better reconstruction leads to worse generation.
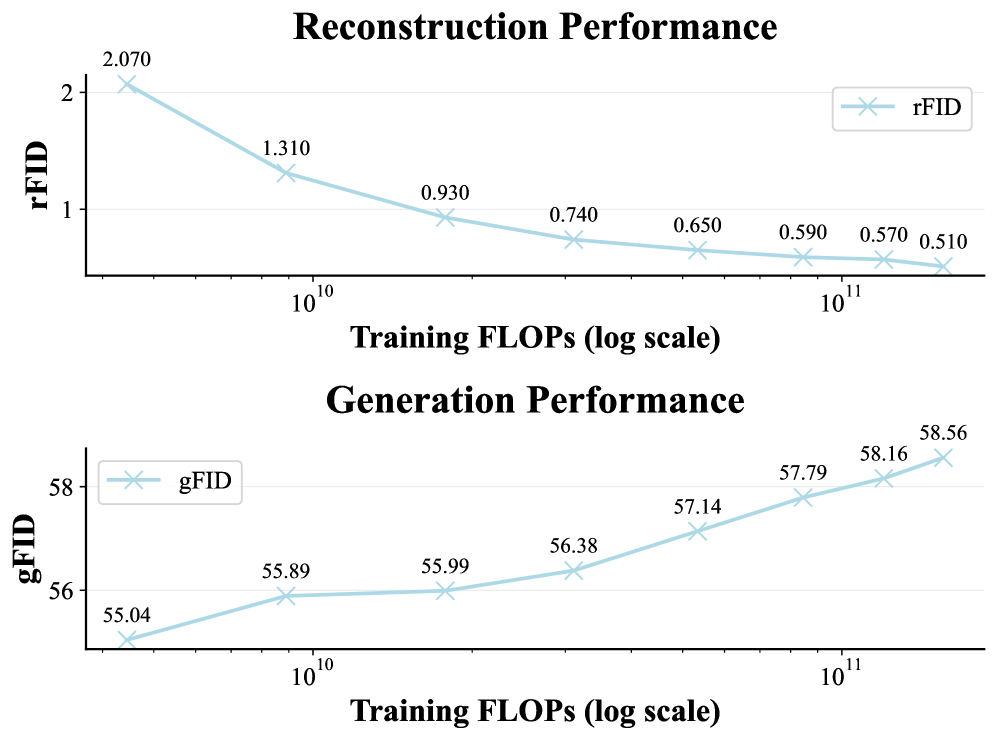
Figure 4: Scaling with reconstruction only. As training compute increases, rFID improves (0.5) but generation degrades (gFID rises from 55.04 to 58.56).
3. VTP Achieves True Scaling Properties
By adding representation learning objectives (CLIP for cross-modal alignment and/or SSL for spatial-semantic perception), the tokenizer exhibits proper scaling laws where generation performance improves with compute:
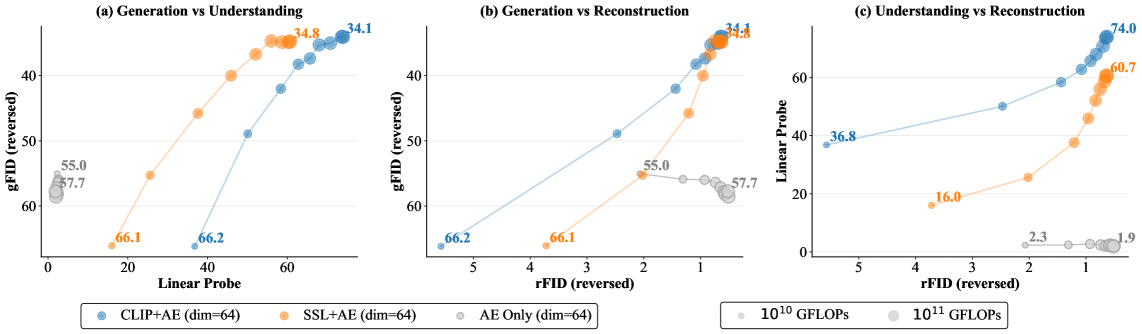
Figure 5: Scalability of CLIP+AE & SSL+AE. Both hybrid approaches show correlated growth in generation and comprehension with compute, while VAE-based tokenizers saturate rapidly.
The full VTP (CLIP+SSL+AE) framework achieves the best scaling behavior:
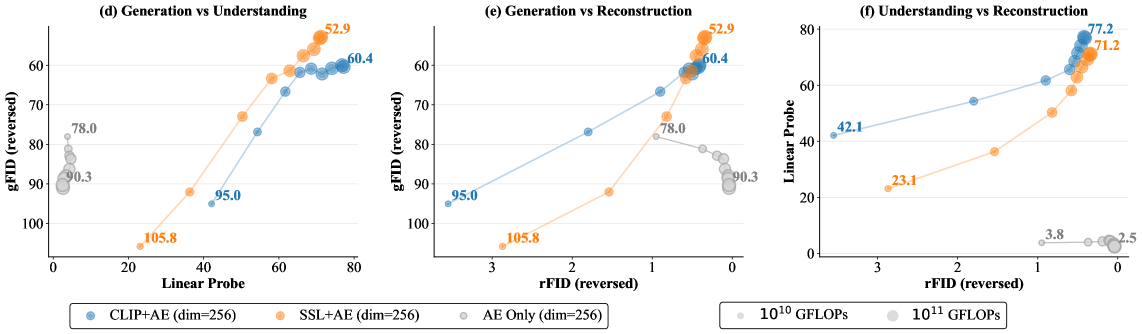
Figure 6: CLIP+SSL+AE achieves gFID=27.8 with 74.9% linear probing accuracy under fixed computational budget, outperforming single-objective variants.
4. Scaling with Data and Parameters
VTP demonstrates unprecedented scalability across dimensions:
Data Scaling: VTP improves significantly with more training data (FID 47.59 → 27.45 from 100K to 100M samples), while reconstruction-only AE stagnates (58.37 → 56.71).
Parameter Scaling: VTP scales with model size (gFID improves from 31.28 → 26.12 → 24.08 as encoder/decoder grow), while AE remains stuck at ~57 regardless of parameters.
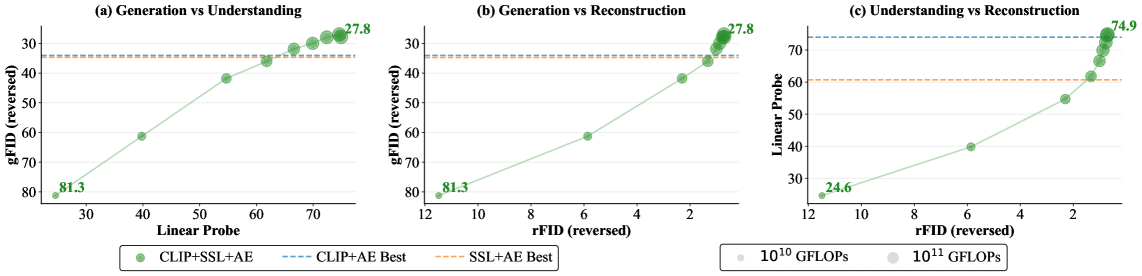
Figure 7: (a) Data scaling, (b) Encoder scaling, (c) Decoder scaling. VTP shows consistent improvement with increased scale, unlike conventional AE.
5. Final Performance & Convergence
After large-scale pre-training, VTP delivers:
- 78.2% zero-shot accuracy and 0.36 rFID on ImageNet
- 4.1× faster convergence in generation training compared to distillation-based methods like VA-VAE
- 65.8% FID improvement when scaling compute 10× (conventional AE stagnates at 1/10 FLOPS)

Figure 8: Reconstruction quality comparison showing VTP's superior color accuracy and texture preservation.
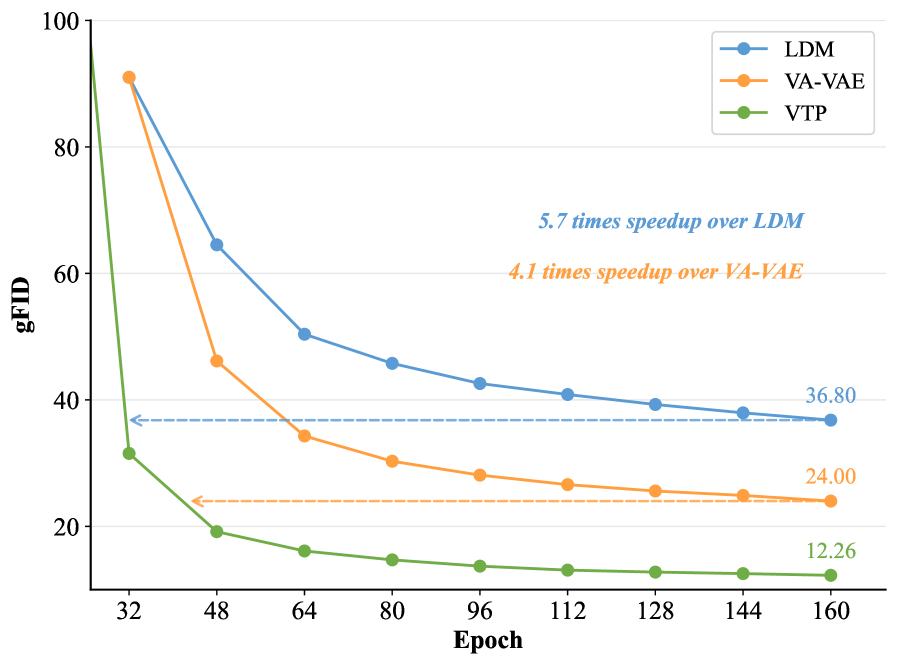
Figure 9: Generation convergence comparison. VTP achieves faster convergence and higher performance ceiling than distillation approaches.
Summary Table
| Method | Understanding | Reconstruction | Generation | Scalability |
|---|---|---|---|---|
| Standard AE (Reconstruction only) | Poor | Good | Poor | Saturates early |
| VA-VAE (Distillation) | Good | Moderate | Moderate | Limited ceiling |
| VTP (CLIP+SSL+AE) | 78.2% | 0.36 rFID | Best | Scales with FLOPs/data/params |
The key innovation is that without modifying the downstream DiT training configuration, simply investing more compute in pre-training the VTP tokenizer achieves dramatic improvements in generation quality—something impossible with traditional reconstruction-only tokenizers.




Models citing this paper 3
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper